The Data Bottleneck in AI Today:
High quality ata is one of today’s most valuable resources. However collecting real data is not always an option e.g. due to legal restrictions. But synthetic data, consisting in slightly modified copies of existing real-world observations, s used to train machine learning models, can be a good alternative to rely on for training and testing machine learning models.
Synthetic times series minimc characteristics of the original data as long as the temporal dynamics is preserved. In this case the synthetic dataset is a perfect proxy for the orignal time series, since it contains the same information and represents the same underlying data generating process, but is free from legal restrictions.
The MIT Tech Review recently included synthetic data generation in its top ten breakthrough technologies in 2022.
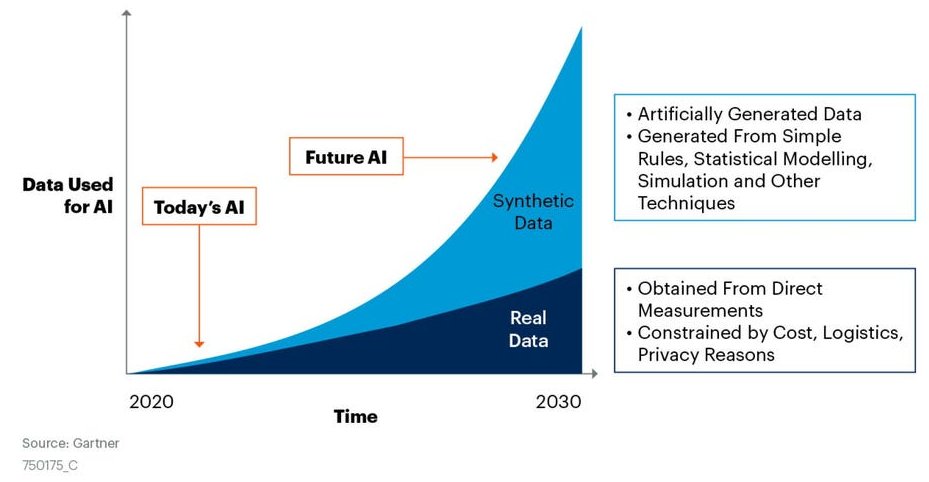
The key reasons, a business may consider using synthetic time series:
- Synthetic data may be way cheaper and faster to generate than it would be to collect from real world events.. Synthetically generated data mitigates data scarcity and improves the statistical performance of ML models as well as their generalisation e.g. by solving imbalance problems.
- There are cases, in which data are rare or dangerous to accumulate e.g. in case of unusual fraud or real live anomalies e.g. in case of road accidents of self-driving vehicles or side effects of drugs. In such cases, we can substitute the unwanted events by synthesized data.
- When sensitive data must be processed or given to third parties to work with, privacy issues must be taken into consideration. Thus future researchers are not able to use them to develop and compare new research.
- Proprietary data assets provide an enduring competitive advantage for AI-startups that have given e.g. only the tech giants in the last 20 years a crippling market dominance, since getting data was always a slow and costly process. Fully synthesized data can be easily controlled and adjusted.
- Synthetic data open a series of doors for companies. Unlocking collaboration at an organizational or industry level, safely and efficiently sharing data, complying with data privacy regulations, facilitating innovation by unlocking new applications such as churn modeling in insurance, identifying money-laundering patterns in finance or detecting cancer in healthcare.



